





Azure Data Factory wordt door Growteq dagelijks gebruikt om data uit verschillende systemen te ontsluiten en op te nemen in datawarehouses. Vandaag wil ik jullie meenemen in hoe Data Factory je snel onderweg helpt met het opzetten van een pijplijn voor het verplaatsen van Data met behulp van de Copy Data tool.
Data Factory biedt out-of-the-box een ruim aantal opties voor databronnen die gemakkelijk zijn te ontsluiten, bijvoorbeeld Google Ads, Salesforce en een scala van database connectoren. Veel van deze bronnen zijn bekend bij Growteq en worden in verschillende projecten reeds ontsloten. In deze tutorial maken we gebruik van een Azure Blob Storage als bron en als doel om de werking van de Copy Data tool te demonstreren. Een Azure Blob Storage is een opslagmedium voor objecten in de Cloud voor allerlei soorten gegevens.
Vereisten voor deze tutorial
Casus
Elke maand wordt er in onze Blob Storage een tweetal JSON-bestanden geüpload die afkomstig zijn van onze energieleverancier met meterstanden van water en elektriciteit van ons kantoor. Om inzicht te kunnen krijgen in ons maandelijkse verbruik van elektriciteit willen we deze data in ons datawarehouse toe te voegen. De tutorial vandaag zou een eerste stap in dit proces kunnen zijn, het verplaatsen van de elektriciteit-data naar een aparte container.
Stap 1: Aanmaken van een data factory
Navigeer in je browser naar www.portal.azure.com, klik op ‘Create a resource’, zoek naar ‘Data factory’ en klik tenslotte op create.
Vervolgens vullen we de basisinformatie voor een data factory zoals hieronder weergegeven. Bij de subscription en resource group vul je de gegevens in die je voor de tutorial wilt gebruiken.
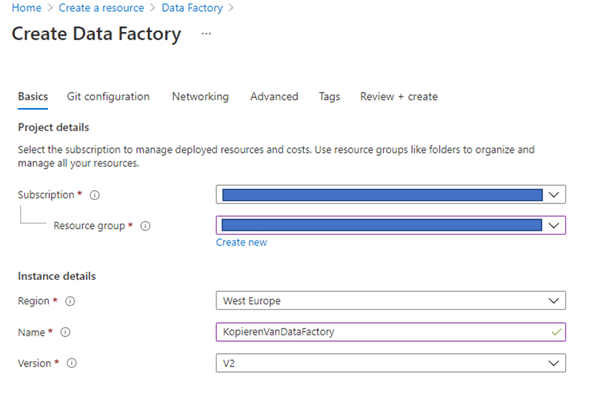
Vervolgens klikken we op create en Azure zal de resource aanmaken. Nadat dit gebeurd is kunnen we via de resource group naar de Data factory navigeren en openen we de Data Factory studio. Dit is de knop onder getting started.
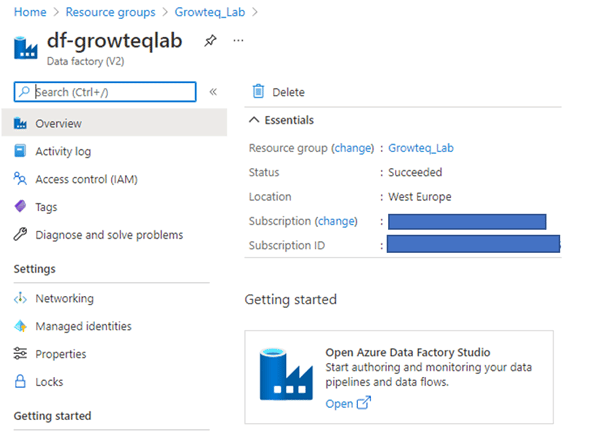
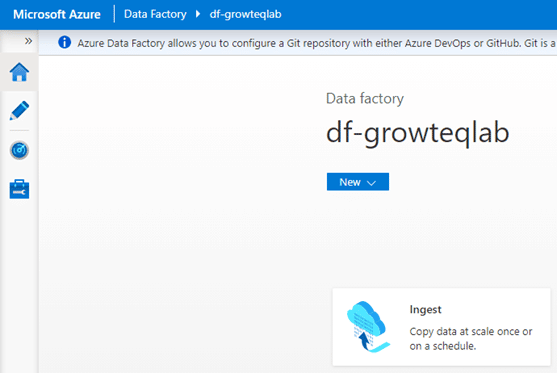
Stap 2: Het gebruik van de Copy Data tool
Op de startpagina van Data Factory kiezen we voor de ingest optie om de Copy data tool te starten.
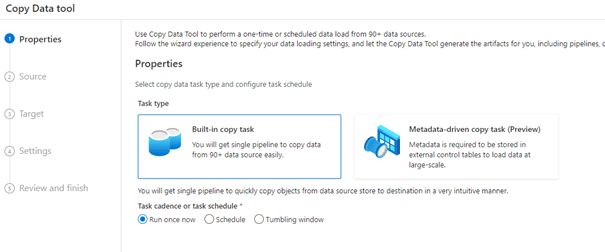
De Properties-stap van de Copy data tool geeft 2 opties voor het kiezen van taken een Built-in copy task en Metadata-driven copy task. We kiezen voor de Built-in copy task voor een simpele data verplaatsing. Daarnaast kunnen we de frequentie van uitvoeren voor de taak selecteren, deze blijft voor nu op ‘Run once now’ staan. De frequentie van uitvoeren kan op een later moment nog worden aangepast.
In de Source-stap configureren we waar de data vandaan moet komen. In ons geval is dat de Azure Blob Storage container waarin de 2 bestanden staan die geüpload zijn. De connectie naar de Blob Storage moet nog gelegd worden in Data Factory. Dit kunnen we doen door het juiste source type te selecteren en een nieuwe connectie aan te maken. Deze connectie moeten we eenmalig toe voegen aan in Data Factory.
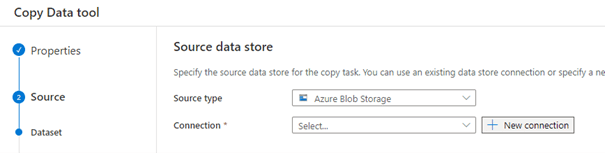
We configureren de connectie naar de Blob Storage door deze een naam te geven en te selecteren uit de subscriptie. De connectie kan getest worden naar de Blob storage. De verbinding leggen naar de Blob Storage ga ik in deze tutorial niet dieper op in. We klikken op create om de connectie aan te maken.
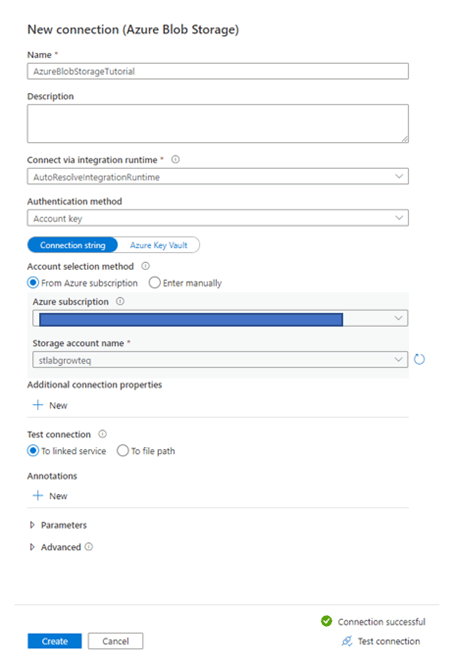
Terug in het scherm van de Copy Data tool kunnen we uit de Blob Storage een bestand of map (container) selecteren via Browse. In ons voorbeeld heet de container met de twee bestanden ‘energy’ en willen het bestand ‘electricity’ selecteren. De filtermogelijkheden onder aan het scherm mogen leeg gelaten worden.
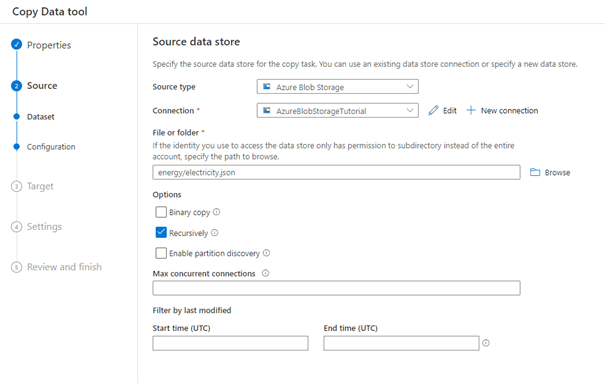
We klikken op Next en gaan naar de volgende stap waarin we het type bestand configureren wat we willen verplaatsen, in ons geval is dat een JSON-bestand. We selecteren deze optie bij File format en kunnen onze data previewen en meteen testen of de instellingen juist zijn. Daarnaast vinken we de check-box ‘Export as-is to JSON-files or Azure Cosmos DB collection’ aan om het volledige bestand over te zetten. We kunnen zelf nog kolommen buiten het bestand toevoegen, om bijvoorbeeld het pad van het bestand mee te geven.
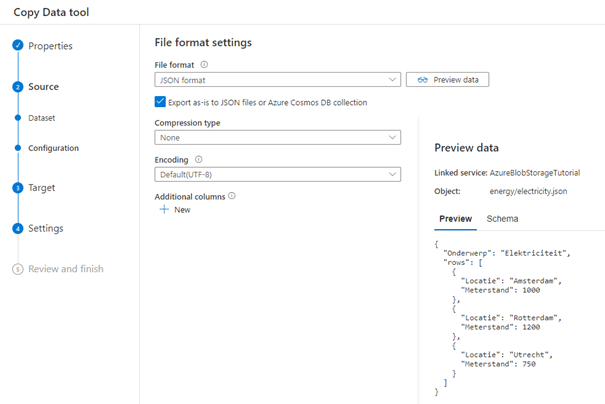
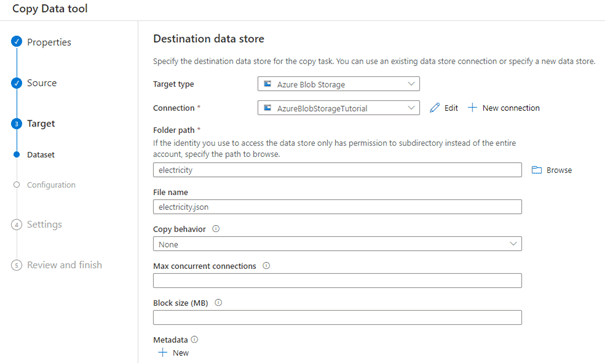
We klikken op next om het doel te configureren in de Target-stap. Ook in dit scherm kunnen we de connectie naar de Blob Storage selecteren om het ‘electricity’-bestand in te plaatsen. We kiezen bij Folder path de nieuwe container die als doel gebruikt wordt, in ons geval ‘electricty’. De overige opties kunnen leeg worden gelaten.
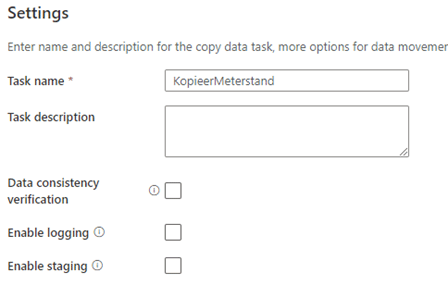
We kunnen bij de Settings-stap de taak een naam en omschrijving geven om deze van basisinformatie voorzien. We kunnen een data consistentie check doen tussen de bestanden, logging aanzetten (Slaat logs op in een Blob Storage) en we kunnen bestanden ‘Stagen’. Het opnemen van een Staging-stap kan van pas komen bij het kopiëren van gegevens van SQL Server naar de cloud. Staging kan doormiddel van een tijdelijke opslag in Blob Storage.
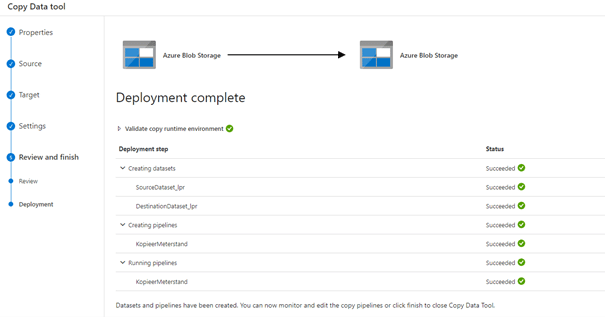
We klikken op next om een overzicht van de stappen te krijgen en vervolgens klikken we weer op next om het ‘Deployment’ te starten waarin de benodigde objecten worden aangemaakt en de pipeline eenmalig wordt uitgevoerd.
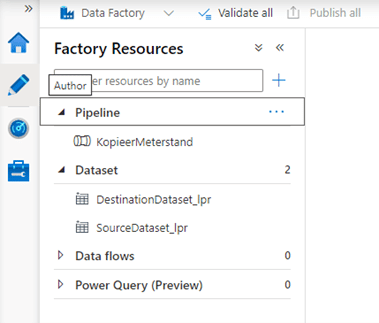
Nadat we op finish klikken kunnen op de Author pagina (Klik op het potlood icoon aan de linkerkant) zien dat de we via de tool een pipeline en onderliggende datasets aangemaakt hebben en deze uit kunnen voeren.
Ten slotte controleren we het resultaat in de Blob Storage of het bestand met succes gekopieerd is. We vinden het bestand in de Blob Storage en kunnen het bestand verder gaan verwerken in het datawarehouse.
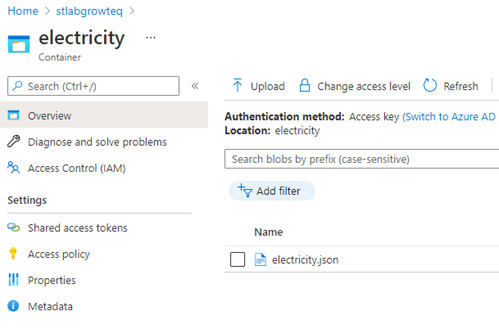
In deze blogpost heb ik jullie meegenomen in de eerste stappen van Data Factory en hoe de Copy Data tool te gebruiken. Deze tool is met allerlei soorten bronnen en doelen te gebruiken.

Wil je meer weten?
Voor meer informatie of een vrijblijvende workshop kun je contact opnemen met Arnoud van der Heiden.





