




Steeds meer applicaties bieden uitgebreide mogelijkheden om gegevens te exporteren, direct vanuit de applicatie of bijvoorbeeld via een webservice. Het voordeel hiervan is dat de gegevens goed gestructureerd beschikbaar zijn, zodat ze verder geanalyseerd kunnen worden.
De gegevens zijn echter niet altijd in een formaat beschikbaar dat ze zonder meer voor data-analyse gebruikt kunnen worden. In onderstaande afbeelding is hiervan een voorbeeld opgenomen.

Om data goed te kunnen analyseren is het belangrijk dat alle gegevens per rij zijn opgeslagen. In bovenstaand voorbeeld staat het grootboekrekeningnummer bijvoorbeeld niet op dezelfde regel als de informatie van de transactieregel. Als het om een paar rijen gaat, kan dit nog makkelijk aangepast worden, zeker als dit in Excel staat. Gaat het echter om enkele duizenden transacties dan wordt dit al een stuk lastiger. En dan zien we nog even af van de grote kans op fouten. Een extra uitdaging ontstaat als de gegevens alleen in de vorm van een PDF beschikbaar zijn.
Er zijn wel tools beschikbaar om een PDF naar Excel of Word om te zetten. Dit biedt niet altijd de gewenste uitkomst. Vaak staan de gegevens dan nog niet netjes gestructureerd in de juiste rijen en kolommen. Het omzetten naar een bruikbaar formaat kost dan nog heel veel tijd, of is door de omvang zelfs geen optie.
Er is een oplossing: het omzetten van het PDF bestand met behulp van de Report Reader van CaseWare IDEA. In dit artikel gaan we een voorbeeld PDF bestand omzetten zodat we deze kunnen inlezen in IDEA voor nadere analyses.
Benodigdheden
In dit artikel maken we gebruik van CaseWare IDEA versie 9.2. In andere versies van IDEA kan de interface er iets anders uitzien.
We maken gebruik van een voorbeeldbestand met daarin gegevens over website gebruik van gebruikers, met extra informatie over wanneer en hoelang gebruikers de websites bezocht hebben. Het voorbeeldbestand kan hier gedownload worden: voorbeeld
Opstarten van de Report Reader
Open IDEA in een werkmap en start de Import Assistent van IDEA op via de optie Import, Desktop:

Kies voor de optie Print rapport en Adobe PDF en selecteer vervolgens het PDF bestand dat omgezet moet worden.

In dit voorbeeld wordt het bestand voorbeeld.pdf gebruikt dat je hier kunt downloaden: voorbeeld.
Opbouw van het bestand
Report Reader opent het bestand en toont de gegevens in het bewerkscherm.
Als je naar de opbouw van het bestand kijkt vallen drie zaken op.
1. Elk gegeven is verdeeld over twee regels:

2. De datum is elke keer maar 1 keer opgenomen voor alle rijen van de betreffende datum;

3. Het bestand is gestructureerd, maar niet elke set van gegevens is precies hetzelfde.
Werken met lagen
De Report Reader van IDEA werkt met lagen. Voor elke regel die je wilt inlezen kun je een laag toevoegen. Meerdere lagen kun je combineren om samen 1 rij te kunnen vormen.
De eerste laag start altijd met de onderste regel van een set van gegevens. In het voorbeeldbestand beginnen we dus met de regel waarin de tijd, de duur van het bezoek en de gebruiker zijn opgenomen.
Maak de eerste laag aan. Sleep hiervoor met je muis van links naar rechts over de regel heen. Er verschijnt een pop-up met de vraag of je een Standaard laag of een Zwevende laag wilt aanmaken.

Kies voor standaard laag en klik op Ja.
Aanmaken insluitingen
Het idee is dat we per laag gaan definiëren hoe de Report Reader de rijen kan identificeren die in de laag moeten worden meegenomen. Hierbij maken we gebruik van insluitingen.
Nadat de laag geselecteerd is verschijnt bovenin het scherm een voorbeeldregel met twee gele lijnen erom heen:

Boven de gele lijnen kunnen nu de insluitingen worden opgegeven.
Hiervoor zijn twee opties:
- Gebruikmaken van de specifieke insluitdefinities van ReportReader
- Insluiten op basis van de tekst in de regel
De insluitdefinities vind je in de bovenste menubalk:

De letters hebben de volgende betekenis:
- T: tekst
- N: numeriek
- S: spatie
- X: niet leeg (dus alles behalve een spatie)
We moeten nu bepalen welke gemeenschappelijke kenmerken de rijen hebben die je aan de eerste laag wilt koppelen. Vaak zijn er meerdere mogelijkheden.
In de eerste laag zien we dat elke regel begint met een vermelding van de tijd met dubbele punten ertussen.
Plaats boven de bovenste gele lijn de insluitdefinitie N, vervolgens een dubbele punt en dan weer een insluitdefinitie N. Het is belangrijk dat de insluitingen precies op de juiste plek worden geplaatst:
Om de insluitdefinities te gebruiken moet je gebruik maken van de knoppen in de bovenste menubalk. Je kunt niet de hoofdletter N typen. ReportReader ziet dit als de gewone letter N waar hij naar moet zoeken. De dubbele punt kun je wel gewoon typen.

Je ziet nu dat in het bestand alle rijen die voldoen aan de insluiting gemarkeerd worden.
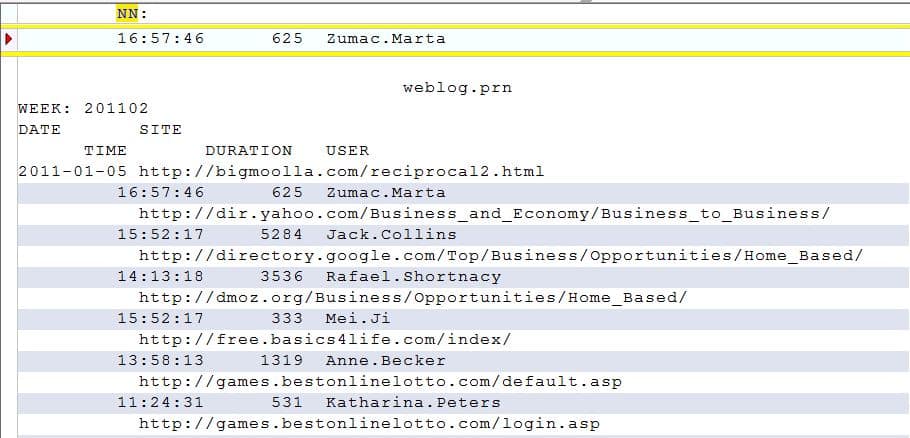
Je moet altijd goed opletten of op basis van de uitsluiting niet teveel regels worden meegenomen. Als we nu hadden gekozen om alleen twee keer de insluitdefinitie NN te gebruiken, dan wordt ook de regel waarin de week is opgenomen geselecteerd:
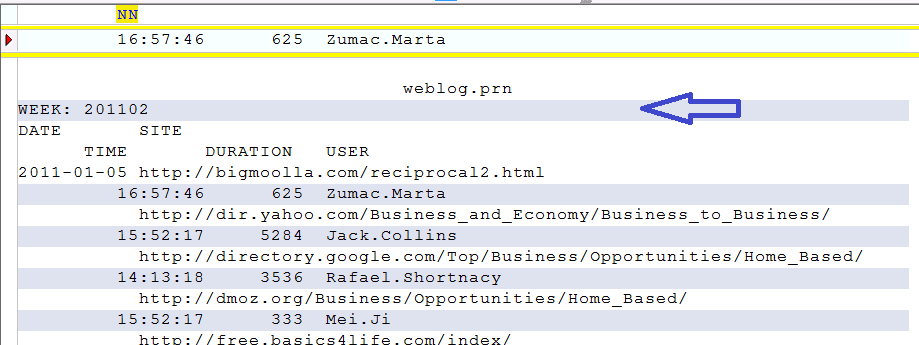
Er moet bepaald worden hoe de regels die meegenomen moeten worden zich onderscheiden van de regels die niet meegenomen moeten worden. Uiteraard moet je ook kijken of er niet teveel regels worden uitgesloten. Typ je als insluiting bijvoorbeeld 16, dan worden alleen de regels die beginnen met 16 meegenomen.
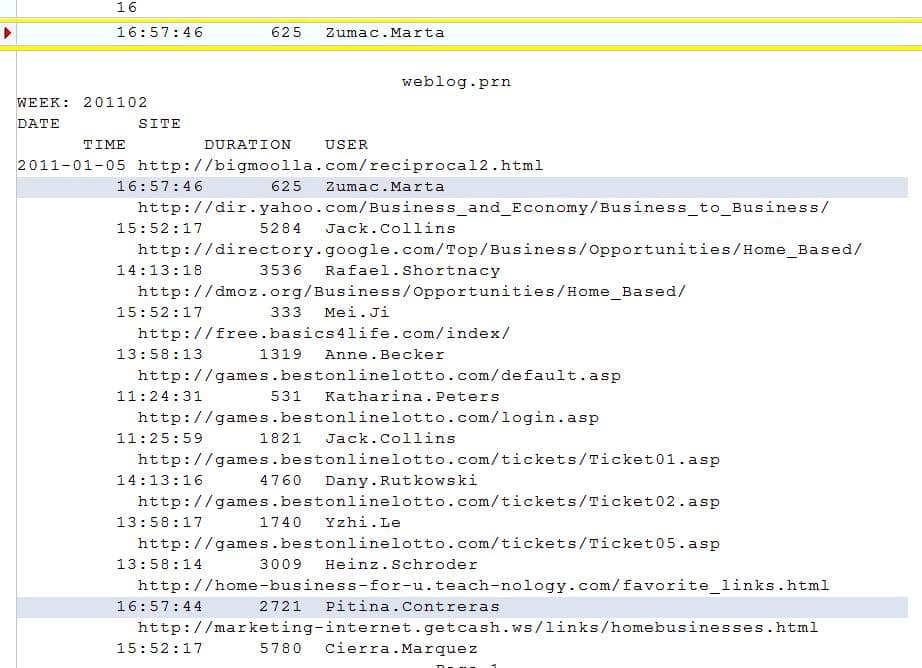
Selecteren velden
Heb je de juiste insluitdefinitie gevonden, dan kun je de velden selecteren die uiteindelijk moeten worden uitgelezen.
Selecteer hiervoor de tekst tussen de twee gele lijnen:
![]()
Ook hier is het van belang om goed op te letten of het op alle regels goed gaat.
Als je in dit voorbeeld alleen uitgaat van de geselecteerde voorbeeldregel gaat het in een aantal onderliggende regels mis. Zo wordt bij de DURATION alle duizendtallen niet meegenomen. Ook worden de namen van de gebruikers deels afgekapt.
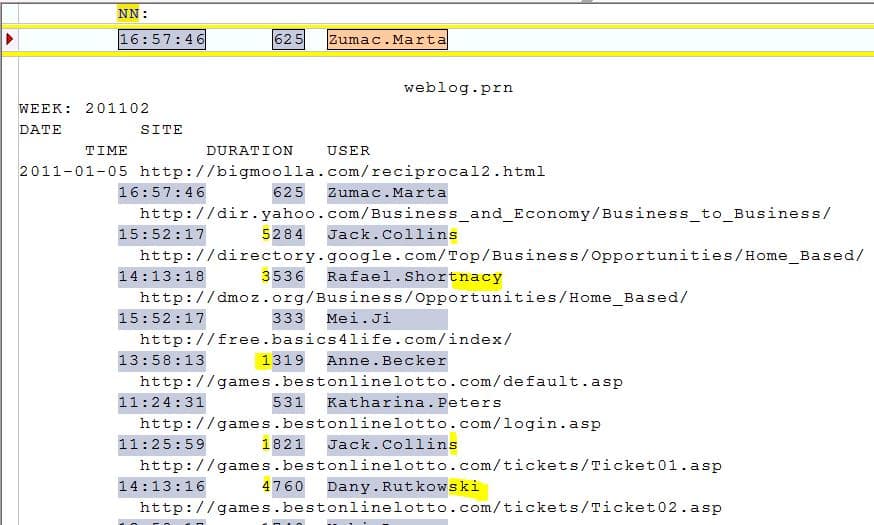
De oplossing is eenvoudig: maak de velden langer zodat op alle regels de gegevens binnen de selectie vallen:
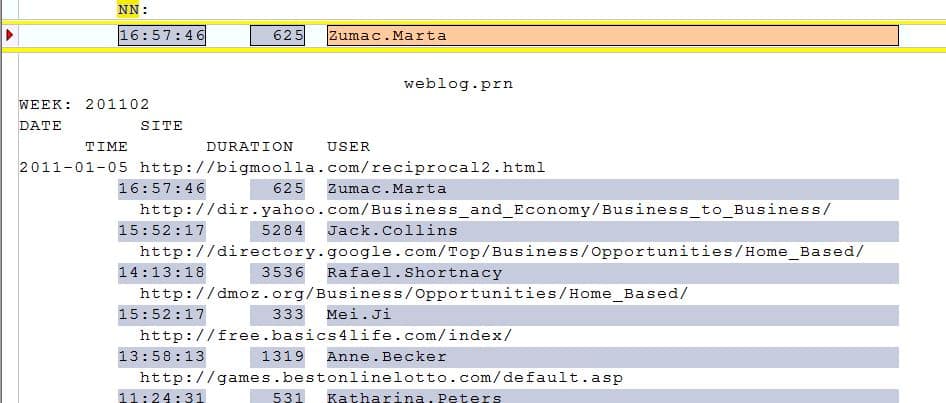
Aanpassen veld namen
Aan de rechterkant van het scherm kun je de details van de velden aanpassen. Selecteer een veld tussen de gele lijnen en vul in het veld details de naam van de kolom in. In dit voorbeeld is het veld met de tijd geselecteerd en is de naam aangepast naar TIME. Report Reader geeft zelf al een type mee op basis van de waarde in de voorbeeldregel. Je kunt dit type hier aanpassen. De keuzes zijn Karakter, Numeriek, Datum en Tijd.
Nadat je de aanpassingen gedaan hebt, kun je het bewerken van deze laag afsluiten door op het groene vinkje in de menubalk te klikken.
Tweede laag
In de volgende stap gaan we de tweede laag koppelen.
In het voorbeeldbestand zijn dit de regels waarin de website adressen zijn opgenomen. Hier zijn nog twee varianten in. De regel waarin de datum is opgenomen is namelijk anders de overige regels van dezelfde datum.
Begin met het selecteren van de regel met het webadres door met de linkermuisknop te slepen over de rij. Het is hier wel belangrijk om de regel te selecteren die hoort bij de regel uit de eerst laag, anders worden de verkeerde regels gekoppeld.
In dit voorbeeld kiezen we dus de regel met het webadres waar ook de datum instaat. In dit geval maakt het niet uit dat de regel met de datum anders is dan de andere regels. In deze laag gaan we namelijk alleen nog maar het webadres ophalen. Creëer in dit geval een zwevende laag.
Er zijn meerdere mogelijkheden om de juiste rijen met de webadressen te identificeren. Hier kiezen we ervoor om de tekst http te typen.
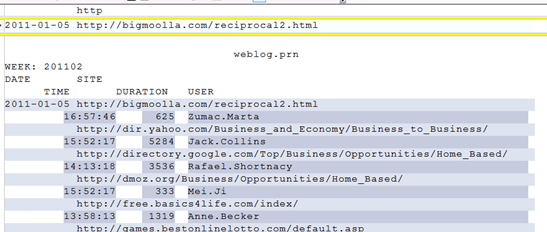
Je ziet dat alle regels zonder datum worden geselecteerd, dat is ook de bedoeling. Het voordeel van een zwevende laag is dat de insluitingen niet precies op dezelfde plek hoeven te beginnen. Als je in het bestand naar pagina twee scrolt dan zie je dat daar een webadres staat die helemaal voor in de regel begint.
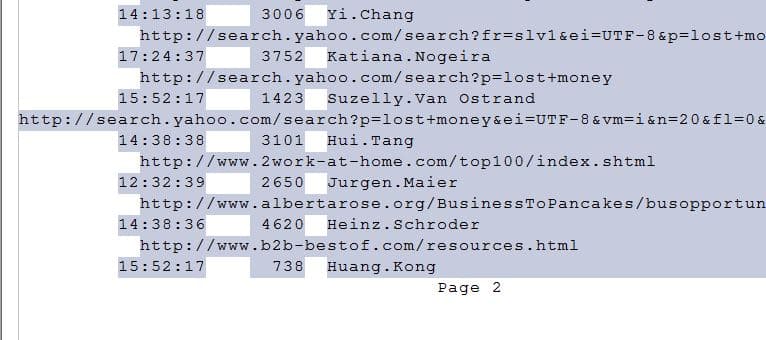
Doordat we een zwevende laag hebben gecreëerd worden deze rijen toch meegenomen. ReportReader zoekt in elke regel naar de eerste voorkomende combinatie van de opgegeven insluitingen. In dit geval dus de tekst ‘’http’.
Maak nu een veld aan waar de website in wordt opgeslagen. Maak het veld breed genoeg zodat de hele website in alle regels wordt meegenomen.
Wijzig de naam in de velddetails in WEBSITE:

Sluit de laag weer af met behulp van het groene vinkje.
Laag drie..
We hebben nog één laag nodig: de laag waarin we de datum toevoegen. Selecteer wederom de regel waarin de datum en het webadres staan. Dit is dus dezelfde rij als van laag twee. Maak hier een standaard laag van.
Voeg de insluitingen toe om de regels te identificeren waarin de datum is opgenomen.Hier kiezen we ervoor om vier keer de insluitdefinitie N op te nemen:
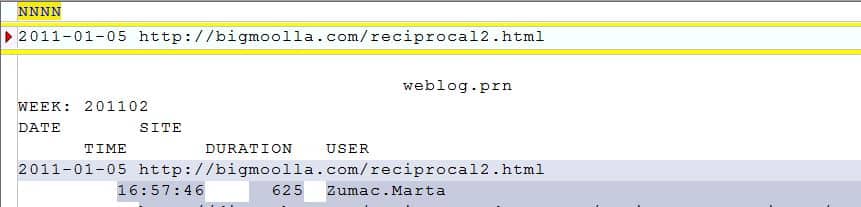
Selecteer de datum om er een veld van te maken. Pas in de velddetails de naam aan naar DATE. Zorg dat het veldtype staat op Datum. Belangrijk is om na te gaan dat het ‘Masker’ goed staat. Zorg dat het masker op YYYY-MM-DD staat.
Sluit het bewerken van de laag af middels het groene vinkje.
Controleren van de invoer
In de menubalk is een knopje waarmee je een voorbeeld kan bekijken hoe de gegevens zullen worden ingelezen.

Als je naar het voorbeeld kijkt zie je dat de datum wel bij de eerste rij is opgenomen, maar niet bij de volgende rijen:
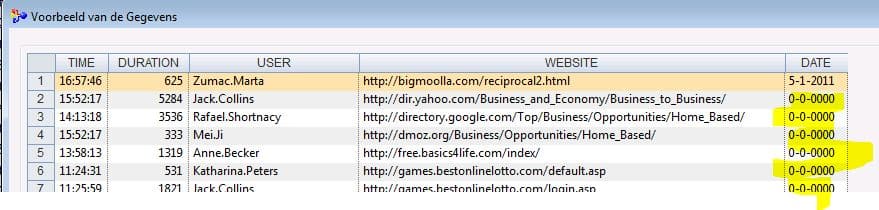
Het datumveld willen we toevoegen aan alle rijen totdat er een nieuwe rij met een datum staat, waarna we willen overgaan naar de nieuwe datum.
Sluit het database voorbeeld af en klik op de knop Lagen manager:

Selecteer Laag 3 en kies bewerken:

Ga naar het veld details van het datumveld en pas de waarde bij de optie Lege Cellen (onder Attributen) aan van ‘Blanco laten’ naar ‘gebruik waarde van het vorige record’.

Sluit de laag af met het groene vinkje en ga weer naar het database voorbeeld.
Je ziet dat nu de datum wel gevuld is voor alle rijen:
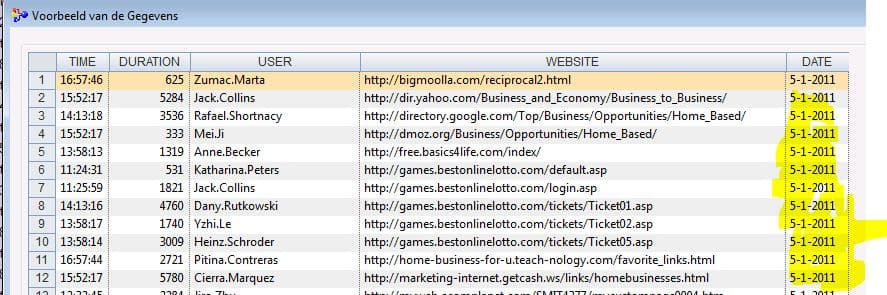
Inlezen in iDEA
Het bestand is nu helemaal klaar om in te lezen. Kies nu eerst voor Sjabloon Opslaan in de menubalk.

Er wordt een bestand opgeslagen waar de insluitingen in zijn opgenomen, zodat je deze nog een keer kunt gebruiken.
Kies vervolgens voor Importeren in IDEA om de import op te starten.

Pas eventueel de databasenaam aan en klik op Finish.

En voilá: in IDEA staan alle rijen die nu verder geanalyseerd kunnen worden.

Afsluiting
Afhankelijk van de opbouw van het PDF bestand kan het soms even puzzelen zijn om de juiste insluit definities te vinden. In sommige gevallen is het soms handiger om het inlezen in een paar aparte stappen te doen en de bestanden vervolgens in IDEA te combineren.
Met behulp van de ReportReader hebben we in ieder geval uitgebreide mogelijkheden om toch de gegevens uit PDF bestanden te kunnen gebruiken voor data-analyse.