





Binnen Growteq zijn we de laatste jaren steeds meer aan het ontwikkelen op het gebied van data analyse. Data kan voor allerlei doeleinden worden gebruikt en een toepassing die erg tot de verbeelding spreekt is de inzet van data om gericht producten aan te bieden aan de juiste koper. Dit kan bijzonder waardevol zijn voor bedrijven die zo optimaal mogelijk hun klantenkring willen bedienen. Veel mensen denken dat dit is voorbehouden aan de grote tech bedrijven als bol.com en Amazon. In deze blog laat ik zien dat met de juiste stappen een ‘recommendation’ model voor iedereen bereikbaar is. Er zijn verschillende manieren om een ‘recommender’ te bouwen, van exploratieve analyses tot heavy duty machine learning. Ongeacht welke methode wordt gekozen, zonder de juiste data kom je er niet.
Hieronder leg ik uit hoe ik een eerste algoritme heb gemaakt dat bepaald of een koper een nieuw product interessant vindt, gebaseerd op wat die koper al eerder heeft gekocht. Als basis voor het algoritme heb ik een dataset gebruikt met de volledige aankoopgeschiedenis van de afgelopen 3 jaar. De dataset bevat zowel gegevens over de klant, zoals locatie en leeftijd, als een uitgebreid aantal kenmerken van de gekochte producten zoals kleur, leeftijd, merk, type, model, en meer.
Het uitgangspunt van het algoritme is alle kenmerken van de kopers en producten te vergelijken zodat er per koper inzicht ontstaat welke producten hij of zij nog meer interessant zou kunnen vinden.
Voorafgaande aan de analyse is een selectie van kenmerken meegenomen waarvan goed beredeneerd kon worden dat deze een belangrijke bijdrage leveren aan de keuze voor een product.

Sommige kenmerken zijn doorlopende, continue waarden met een groot bereik (zoals prijs). Om de vergelijking te vergemakkelijken zijn deze opgesplitst in categorieën of klassen. Deze stap is reeds in de database uitgevoerd.
Per nieuw object is berekend of een koper geïnteresseerd is door deze te vergeleken met alle voorgaande aankopen van de koper. Voor elk kenmerk wordt een score berekend van 0 of 1, als een kenmerk perfect overeenkomt krijgt het de hoogste score, bij afwijkingen de laagste. Voor sommige kenmerken is het logischer hier een aantal treden in aan te brengen, met een steeds lagere score naarmate de afwijking groter wordt. Voor leeftijd en prijsklasse bijvoorbeeld is het redelijk om de nabijgelegen klasse een hogere score te geven dan een klasse die er ver vandaan ligt.
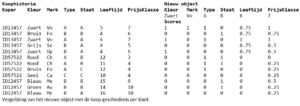
Om te corrigeren voor de aantallen en variatie in aankoop gedrag wordt per koper de mediaan van de scores berekend.

Niet elk kenmerk telt even zwaar mee in de keuze. Hier kunnen allerlei ingewikkelde berekeningen op los worden gelaten maar dit hoeft niet. Er kan ook per kenmerk beredeneerd worden hoe belangrijk het is. Een antiek handelaar zal zo bijvoorbeeld de leeftijd en staat van een object heel erg belangrijk vinden, een autohandelaar is gespecialiseerd in een bepaald merk en type. In deze eerste versie is ervoor gekozen om per kenmerk handmatig gewichten mee te geven:

De scores worden vermenigvuldigt met het gewicht en opgeteld naar een totaal score die een surrogaat maat is voor de interesse die een koper heeft voor het nieuwe object.
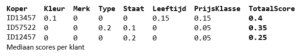
Cijfers zijn niet altijd in één oogopslag duidelijk, daarom zijn er categorieën gemaakt van A t/m D om aan te geven hoe goed de match is met een koper. Op basis hiervan kan een object gericht worden aangeboden aan een koper. De afkappunten zijn arbitrair bepaald.
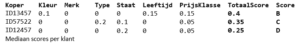
Het algoritme is het een mooie eerste opzet om een ‘recommender’ te maken met een beperkte set data en een beetje gezond verstand. Mogelijke verbeterpunten voor het algoritme kunnen zijn:
- Per koper data-gedreven welke kenmerken het meeste bijdragen.
- De relatieve gewichten voor de scores afstemmen met een inhoudsexpert.
- Meer object-kenmerken meenemen.
- De afkappunten voor de scores afstemmen met een inhoudsexpert.

Meer weten over onze oplossingen?
Onze consultants hebben veel ervaring binnen een grote verscheidenheid aan branches.
Eens verder brainstormen over de mogelijkheden voor jouw organisatie?
Maak kennis met onze specialist Arnoud van der Heiden.





